📜 Līla
A Unified Benchmark for Mathematical Reasoning
(EMNLP 2022)
About
Mathematical reasoning skills are essential for general-purpose intelligent systems to perform tasks from grocery shopping to climate modeling. Existing math reasoning datasets are too narrow in scope to holistically evaluate models' general math reasoning abilities. Towards evaluating and improving AI systems in this domain, we propose Līla, a unified mathematical reasoning benchmark consisting of over 140K natural langauge questions from 23 diverse tasks. We also introduce Bhāskara, a foundation model for mathematical reasoning trained on Līla.

Benchmark
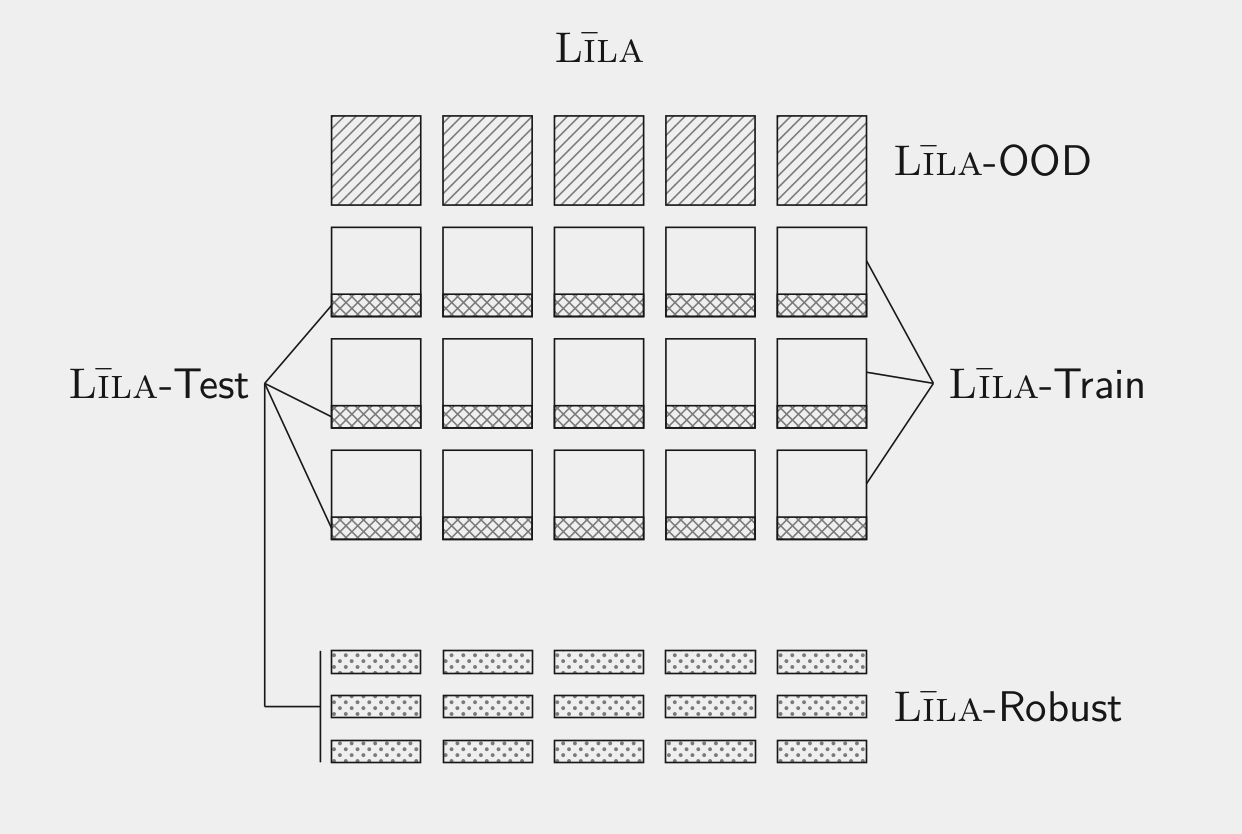
Līla is a comprehensive benchmark for mathematical reasoning with over 140K natural language questions annotated with Python programs and natural language instructions. The data set comes with multiple splits: Līla-IID (train, dev, test), Līla-OOD (train, dev, test), and Līla-Robust. To help measure progress in mathematical reasoning, we host a public leaderboard for Līla.
We gladly accept contributions to Līla. If you have a mathematical reasoning dataset, please open a issue and send us an email and we will work with you to incorporate it!

Our benchmark is named after Līlavati, a 12th century mathematical treatise on arithmetic that covers topics like arithmetic and geometric progressions, indeterminate equations and combinations. It is also widely known for the extensive number of math word problems. The author, Bhāskara II is known for fundamental and original contributions to calculus, physics, number theory, algebra, and astronomy. Read more about Bhāskara in our blog post.
Model
Bhāskara is a multi-task mathematical reasoning model. Bhāskara is a fine-tuned version of EleutherAI's GPT-Neo-2.7B on the Līla-IID-train dataset. In our paper, we show that further fine-tuning Bhāskara on new mathematical tasks outperforms fine-tuning similarly sized models. Because our model is available on HuggingFace Hub, using it is as easy as:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("allenai/bhaskara")
model.generate("Question: What is the square root of 15?\nAnswer:")Authors

Arizona State Universty

The Allen Institute for AI

UC Los Angeles

Harvard Universty

The Allen Institute for AI

Arizona State Universty

Georgia Institute of Technology

The Allen Institute for AI

The Allen Institute for AI

The Allen Institute for AI

The Allen Institute for AI
Contact
Questions? Want to get in touch? Contact Matthew Finlayson (matthewf@allenai.org) or open an issue on GitHub.Cite us
@INPROCEEDINGS{Mishra2022Lila,
author = {
Swaroop Mishra
and Matthew Finlayson
and Pan Lu
and Leonard Tang
and Sean Welleck
and Chitta Baral
and Tanmay Rajpurohit
and Oyvind Tafjord
and Ashish Sabharwal
and Peter Clark
and Ashwin Kalyan},
title = {Lila: A Unified Benchmark for Mathematical Reasoning},
booktitle = {Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
year = {2022}
}





